GraalVM:在容器内部署Java本地镜像
GraalVM是一款可以运行不同语言程序的高性能虚拟机。目前它能运行包括Java, Scala, Kotlin以及Groovy在内的JVM语言。它还支持JavaScript,Node.js, Ruby, R, Python以及LLVM能支持的原生语言。GraalVM有许多用途,对于云部署及容器领域,其中的一项特性可能最让人兴奋不已。它可以将JVM字节码提前编译成本地可执行文件或共享库,而生成的二进制文件并不依赖JVM来执行。
这个可执行文件可以当作一个独立的应用在容器内运行,同时它的启动时间非常非常迅速。除此之外,GraalVM本地镜像运行时内存占用低,对云部署也是一个极大的诱惑。
开始
我们先从头开始,创建一个GraalVM的本地镜像。首先需要有一个它的发布版;可以从它的网站上下载。社区版或企业版都可以。
解压后,将GraalVM的目录设置到$GRAALVM_HOME变量中;可以将$GRAALVM_HOME/bin(Mac上是 $GRAALVM_HOME/Contents/Home/bin)加到$PATH中,这样更方便一些。完成之后,用来创建本地镜像的工具native-image就算是安装好了。执行下$GRAALVM_HOME/bin/native-image --version来检查下设置是否正确。
我们用一个小的程序来做下演示。将https://github.com/graalvm/graalvm-demos/克隆一份,然后进到native-list-dir目录中。在这里可以找到一个ListDir.java类,它会遍历文件系统,将查找到的文件信息打印出来。代码很简单:
public class ListDir { public static void main(String[] args)
throws java.io.IOException {
String root = ".";
if(args.length > 0) {
root = args[0];
}
System.out.println("Walking path: " + Paths.get(root));
long[] size = {0};
long[] count = {0};
try (Stream<Path> paths = Files.walk(Paths.get(root))) {
paths.filter(Files::isRegularFile).forEach((Path p) -> {
File f = p.toFile();
size[0] += f.length();
count[0] += 1;
}); }
System.out.println("Total: " +
count[0] + " files, total size = " + size[0] + " bytes");
}
然后把它编译成.class文件,因为native-image只能识别字节码,不过正因为这样它也能支持其它的JVM语言。
运行完javac ListDir.java,然后紧接着,native-image ListDir。
native-image也能用于jar包;不过你得先指定好classpath以及要执行的主类。native-image会对你的应用程序进行静态分析,它还用到了哪些其它的类(包括依赖路径及JDK中的类),然后生成一个可达的类及方法的map表。这么做依赖于一个叫“封闭宇宙(closed universe)”的前提——就是说最终生成的可执行文件中所有字节码在本地镜像的生成阶段都必须是确定的。
分析完成后,会得到一个叫listdir的文件。在macOS上,它就是一个本地系统的可执行文件。它会直接链接到操作系统的库而无需JVM。
文件本身有数M大小。它包括提前编译完成的示例程序本身以及用到的JDK类,比如java.lang下的类或者可能抛出的Exception类。尽管有这么多类,但是这个可执行文件的大小通常也要比运行程序的完整的JDK要小得多。
我们在Java目录下分别执行下java版的程序以及本地可执行文件,再用标准的UNIX命令time去计算下所需的时间:
$ time java ListDir
Walking path: .
Total: 7 files, total size = 8366834 bytes
java ListDir 0.22s user 0.06s system 51% cpu 0.555 total
然后是Graal的本地版本:
$ time ./listdir
Walking path: .
Total: 7 files, total size = 8366834 bytes
./listdir 0.00s user 0.00s system 66% cpu 0.011 total
可以看到输出结果是完全一样的,虽然java版花的时间也不算多,但本地镜像版的用时几乎为0.
一个很重要的原因就是本地镜像在生成的过程中,会先执行类的静态初始块,并将预初始化的数据结构存储在结果堆中。这项功能是可选的,不过它对进一步减少启动时间还是有所帮助的。
不过这项优化也给本地镜像带来了一个很有意思的问题:如果要提前编译某个程序,但它在初始化阶段实例化了生产环境的对象该怎么办,比如说,创建了线程池,打开了文件,或者进行了内存映射?在镜像生成阶段执行这些操作是没有意义的,这通常不会在生产环境执行,而是在持续集成的阶段。如果初始化块的确执行了这些无意义的操作,native-image工具会回退并拒绝进行编译。这个时候你就需要配置一下--delay-class-initialization-to- runtime=classname,让类在运行时再进行初始化。
异常情况处理
生成本地镜像还有一些其它问题是需要额外进行配置的。最常见的问题可能就是反射了。通过反射API,Java程序可以查看类数据,加载额外的类或者进行方法调用。由于反射API支持对类或对象进行完全的动态访问,静态分析无法解析出本地镜像运行所需的所有类。但这并不意味着GraalVM的本地镜像就完全拿反射的代码没有办法了,不过你得提前标识出可能会使用反射的类或方法。它会通过一个JSON格式的文件来配置这些类或文件。假如你有如下两个通过反射互相调用的两个类:
package org.example;
class ReflectionTarget {
public String greet();
}
和
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
System.out.println(
getResult(Class.forName("org.example.ReflectionTarget")));
}
private static Object getResult(Class<?> klass) throws Exception {
Method method = klass.getDeclaredMethod("greet");
return method.invoke(
klass.getDeclaredConstructor().newInstance());
}
}
你需要先提供如下的JSON文件并在命令行参数-H:ReflectionConfigurationFiles=中指定它,才能编译这个文件:
[
{
"name" : "org.example.ReflectionTarget",
"methods" : [
{
"name" : "<init>",
"parameterTypes" : []
},
{
"name" : "greet",
"parameterTypes" : []
}
}
]
该文件会说明哪个类的哪个方法或者构造器会通过反射来访问。同样,如果需要编译成本地镜像的程序使用了JNI,也需要对它进行配置。
或许你会觉得这个配置会很烦人,尤其是使用了反射的代码可能并不是你写的,而是依赖的库中用到的。这种情况下,你可以使用GraalVM提供的javaagent。先运行应用程序然后关联到agent上,它会记录所有用到的反射,JNI等等你需要进行配置的东西:
$ /path/to/graalvm/bin/java \
-agentlib:native-image-agent=trace-output=/path/to/trace-file.json
你可以提供不同的trace文件并重复运行多次,确保所有相关的代码路径都已经执行到,native-image工具能拿到你希望运行的代码的完整信息。
你可以在执行测试用例时运行这个追踪代理。测例用例通常会覆盖最重要的代码路径。(如果没有的话,最好先完善下你的用例。)当trace信息全部收集完毕,你可以将它们转换成native-image所需的配置文件:
$ native-image --tool:native-image-configure
$ native-image-configure process-trace \
--output-dir=/path/to/config-dir/ /path/to/trace-file.json
上述命令会解析trace文件,并生成所需的JSON配置:jni-config.json, reflect-config.json, proxy-config.json, 以及resource-config.json。
完成之后,使用生成的配置文件就很简单了。下面的命令会真正去用到这些配置:
$ native-image -H:ConfigurationFileDirectories=/path/to/config-dir/
还有一个很重要的配置也需要了解一下:--allow-incomplete-classpath。Java应用通常会检查某个类是否在类路径中,然后进行相应的动作。一个典型的例子就是日志配置,它会先检查logback是否可用,可用的话就使用它;否则再看一下log4j2是否可用,可以的话就用log4j2;如果还是没有就再检查下log4j2,依次类推。面对这样的代码native-image又该如何处理呢——它需要检查所有的类,难道要扫描所有的代码路径?解决方案很简单:目前在默认情况下,它是拒绝编译此类代码的,但如果你明确告诉它类路径不完整也能够接受的话,它可以在不引入这些代码路径的情况下进行编译。
native-image生成镜像的过程还有许多其它选项可以进行配置,与前面介绍过的功能类似。通过这些配置,开发人员可以让GraalVM的本地镜像工具能够处理更多的程序。
性能
我们来看下本地镜像的性能如何。前面我们看到,本地镜像的启动时间在毫秒级。但它的吞吐能力如何呢?毕竟我们都知道,相对于启动时间或预热时间而言,JIT编译器能够明显地提升应用的峰值性能。本地镜像性能并不差,但是对于长期运行的应用而言,预热完成之后的JIT编译器可能在性能上更有优势。带着这个疑问,我们用一个基于Netty的web应用来做下测试。
首先,我们通过下述命令构建及生成本地镜像:
$ mvn clean package
$ native-image -jar target/netty-svm-httpserver-full.jar \
-H:ReflectionConfigurationResources=\
netty_reflection_config.json \
-H:Name=netty-svm-http-server \
--delay-class-initialization-to-runtime=\
io.netty.handler.codec.http.HttpObjectEncoder \
-Dio.netty.noUnsafe=true
现在这个本地文件已经是可执行的了,我们给它增加一些负载,看看单个请求的峰值性能能到多少。
我使用的是wrk2来进行基准测试,用它来生成请求并测量响应延迟。在我的MacBook上,我配置了2个线程,最高100的并发请求,最后在2000/s的压力下稳定运行了30秒钟:
$ wrk -t2 -c100 -d30s -R2000 http://localhost:8080/
下面是测试的结果。首先先看下这个示例程序的字节码版本的运行结果,然后再看下本地镜像的。
Java字节码版本:
Running 30s test @ http://127.0.0.1:8080/
2 threads and 100 connections
Thread calibration: mean lat.: 1.386ms, sampling interval: 10ms
Thread calibration: mean lat.: 1.362ms, sampling interval: 10ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.30ms 573.88us 3.34ms 65.01%
Req/Sec 1.05k 181.18 1.67k 78.84%
59802 requests in 30.00s, 5.70MB read
Requests/sec: 1993.21
Transfer/sec: 194.65KB
本地镜像版本,它的结果也非常接近:
$ wrk -t2 -c100 -d30s -R2000 http://127.0.0.1:8080/
Running 30s test @ http://127.0.0.1:8080/
2 threads and 100 connections
Thread calibration: mean lat.: 1.196ms, sampling interval: 10ms
Thread calibration: mean lat.: 2.788ms, sampling interval: 10ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.43ms 715.90us 5.78ms 70.34%
Req/Sec 1.07k 1.37k 5.55k 89.40%
58898 requests in 30.01s, 5.62MB read
Requests/sec: 1962.88
Transfer/sec: 191.69KB
当然了,这并不算是一个严格的测试,不过这个数字表明,在较短的时间内,本地镜像和JDK版本的运行性能是相差不大的。
如果你需要更好的执行性能,可以考虑使用下GraalVM的企业版,它是一个定制化的版本,额外增加了很多加强性能的特性。就本地镜像这项功能而言,企业版除了一般的优化外,还支持PGO优化(profile-guided optimization),你可以先构建好一个镜像,然后增加负载,收集它的运行性能数据,最后根据应用自身的需要来定制优化,生成最终的镜像。这样做的性能能达到与预热后的JIT编译同等的水平。
内存消耗
我们再来看下内存消耗。采用JVM为作为无服务(serverless)应用最常见的问题就是占用内存过高,哪怕只是一次性的任务比如说处理某个请求。(如果你想了解下GraalVM本地镜像会消耗多少内存,不妨告诉你一个数字,前面那个netty应用算上堆内存一共在我本机上占用了30MB)
本地镜像也有垃圾回收的功能。它会运行你的程序然后在运行时收集无用对象,给你一个内存可以无限使用的假象。这不是什么新鲜事,所有JVM都是这么做的。但是JVM通常会让你自己选择使用的垃圾回收的算法,你是期望低延迟,还是消耗CPU最少或是其它。
本地镜像的垃圾回收器和JVM中使用的不太一样。实际上它是一个用Java编写的定制版的垃圾回收器,一款非并行的分代回收器。简单来说,你可以认为它就是JDK8中默认使用的并行回收器的简化版本。它会将堆进行分代,新对象在Eden区中,之后要么被回收掉,要么就进入到老年代。
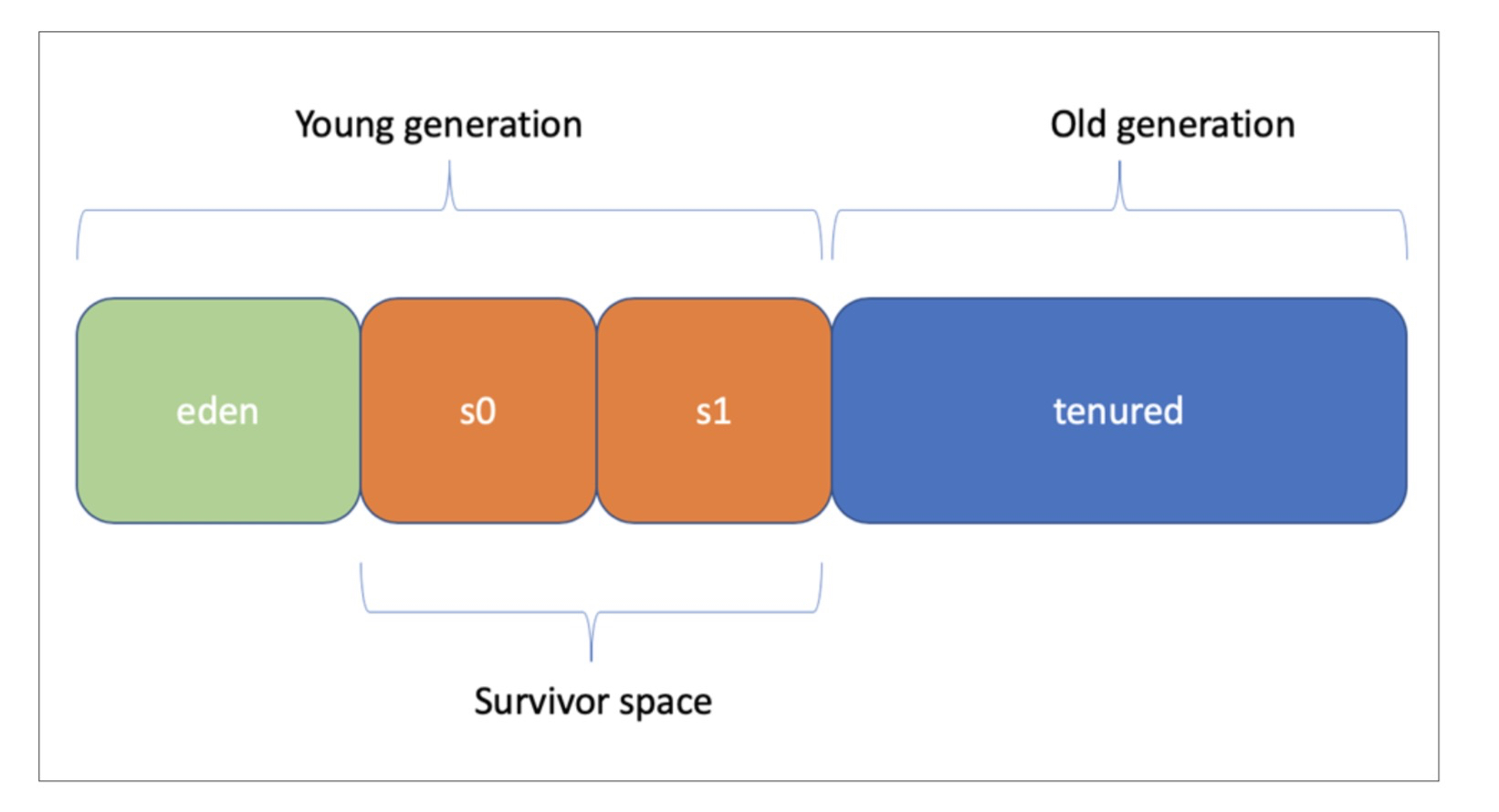
本地镜像也可以进行GC调优。一般可能会需要调整下堆的最大值。可以通过-Xmx命令行参数来进行设置。如果你想了解下本地镜像GC的细节情况,可以通过-R:+PrintGC或-R:+VerboseGC这两个标记来收集每次GC前后的信息。本地镜像通常占用内存更小,一个原因就是它们不需要引入动态加载新类的机制,也不需要存储类的元数据以便进行反射操作,或者在运行时进行类的编译。
结论
总的来说,GraalVM本地镜像为容器内无JVM运行Java程序提供了可能。它还提供了接近于实时的启动速度,以及非常低的运行时内存消耗。这对云部署比如说FaaS平台而言非常关键,你可能会希望对服务进行自动伸缩,或者有计算和内存资源上的限制。
本地镜像只是GraalVM的一个实验特性,目前应用程序还无法很便捷地使用这一特性。不过它已经能支持不少复杂应用,也有一些框架选择了GraalVM作为它们的一种部署方式以便降低使用门槛。如果你在容器内部署应用,并且启动时间和内存占用非常重要的话,GraalVM本地镜像对你而言就非常有价值了。
