使用LangChain来实现大模型agent
agent介绍
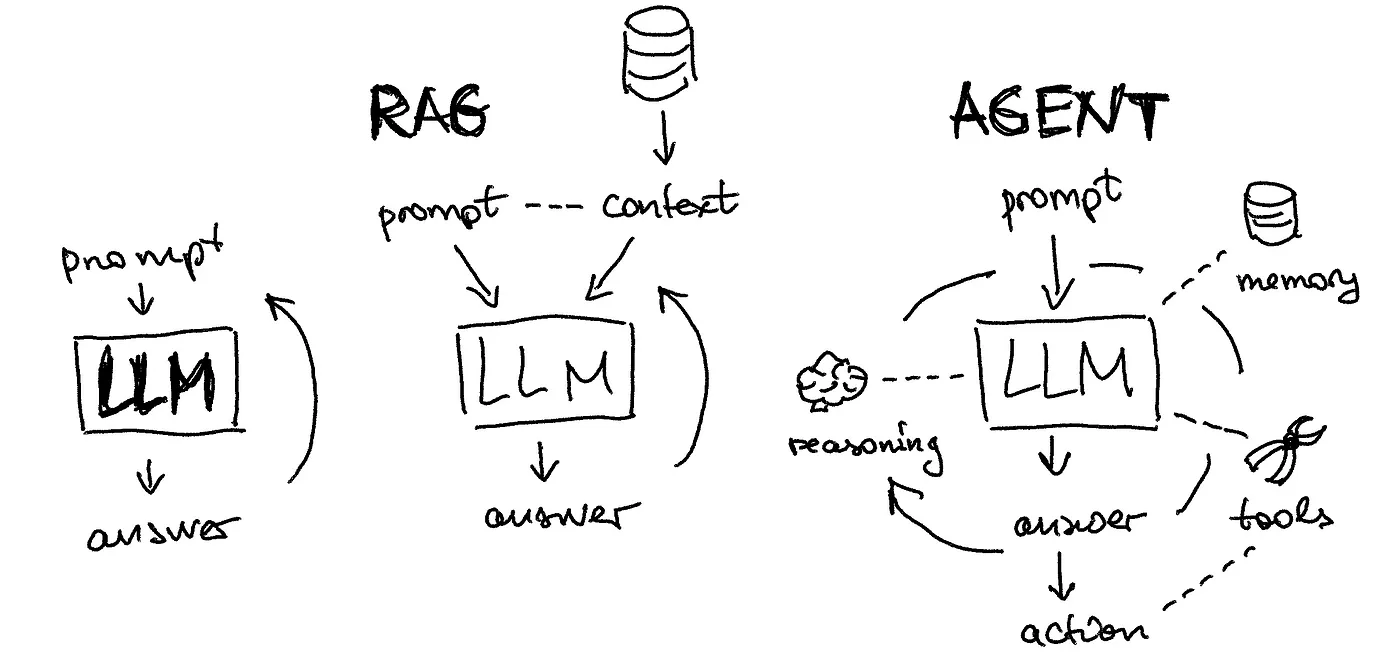
我们先从LLM Agent的各种不同示例开始讲起。虽然很多人在热议这个话题,但很少有人经常在使用它;通常,我们所认为的agent只是大语言模型。来看一个简单的任务,如搜索足球比赛结果并将其保存为CSV文件。可以比较下几种可用的工具:
- GPT-4结合搜索和插件:如这里的聊天记录所示,由于代码错误,GPT-4未能完成任务。
- AutoGPT使用https://evo.ninja/ 至少可以生成CSV的格式(尽管不理想)。
- AgentGPThttps://agentgpt.reworkd.ai/:它把这个任务看成是合成数据生成器,但这并不是我们想要的,聊天记录在这里。
由于可用的工具并不理想,我们先从头开始学习构建agent的基本原理。我参考了这篇文章作为结构参考,但添加了更多示例。
步骤1:规划
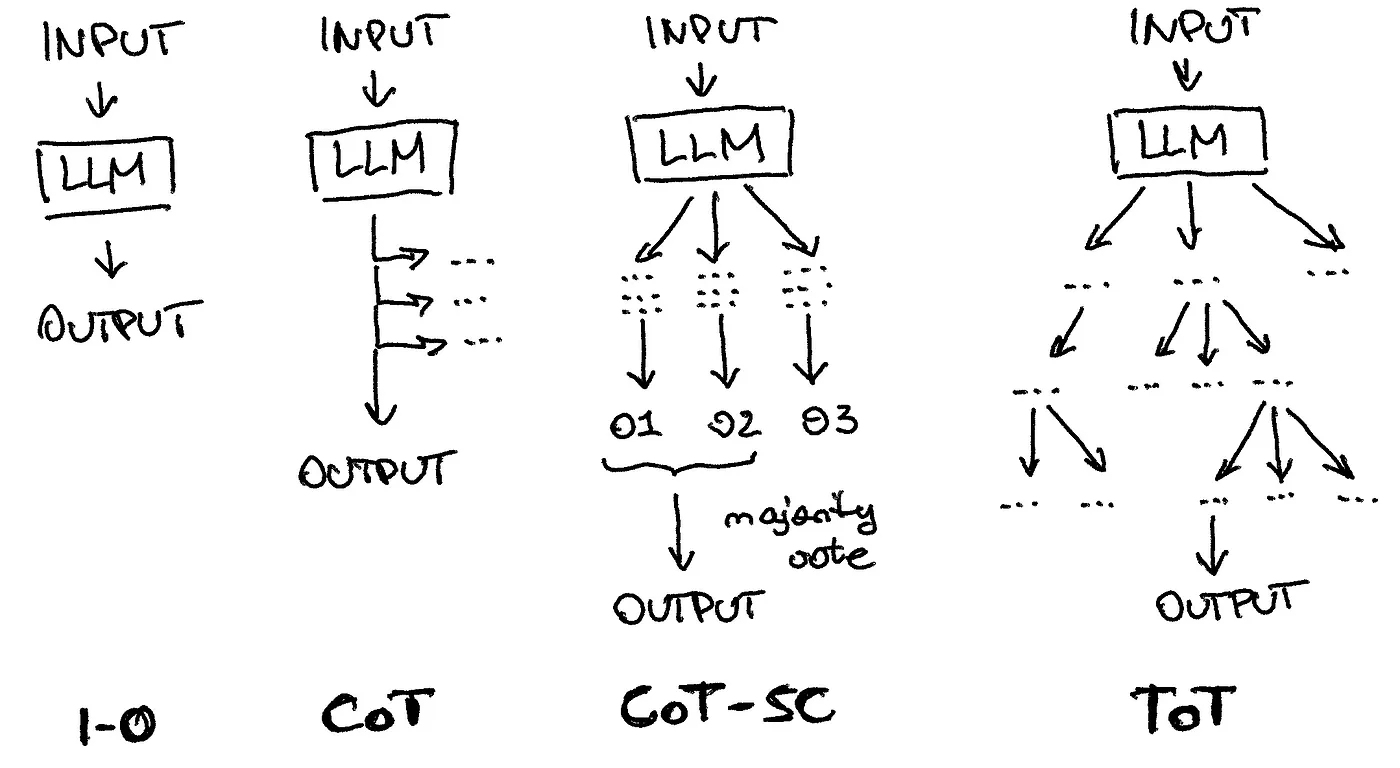
你可能已经接触过各种旨在提升大语言模型效果的技术,比如提供提示,甚至开玩笑地威胁它们。一种流行的技术被称为“链式思维”,它会模型去逐步思考,从而允许自我修正。这种方法已经演变成更高级的形式,如“自我一致性的链式思维”以及更为通用的“思想树”,它会创建、重新评估以及合并多个思想来提供输出。
在这个教程中,我会经常用到Langsmith,来实现LLM应用程序的产品化。例如,在构建思想树提示词时,我会将子提示词保存在提示仓储中并加载它们:
from langchain import hub
from langchain.chains import SequentialChain
cot_step1 = hub.pull("rachnogstyle/nlw_jan24_cot_step1")
cot_step2 = hub.pull("rachnogstyle/nlw_jan24_cot_step2")
cot_step3 = hub.pull("rachnogstyle/nlw_jan24_cot_step3")
cot_step4 = hub.pull("rachnogstyle/nlw_jan24_cot_step4")
model = "gpt-3.5-turbo"
chain1 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step1,
output_key="solutions"
)
chain2 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step2,
output_key="review"
)
chain3 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step3,
output_key="deepen_thought_process"
)
chain4 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step4,
output_key="ranked_solutions"
)
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=["input", "perfect_factors"],
output_variables=["ranked_solutions"],
verbose=True
)
在这里,你可以看到这样推理的结果。这里想强调的是,正确地定义推理步骤并在像Langsmith这样的LLMOps系统中对其进行版本控制的重要性。你还可以在公开存储库中看到其他流行的推理技术示例,例如ReAct或self-ask-with-search。
prompt = hub.pull("hwchase17/react")
prompt = hub.pull("hwchase17/self-ask-with-search")
其他值得关注的方法包括:
- Reflexion(Shinn & Labash 2023):它是一个框架,使得agent可以具备动态记忆和自我反思能力,以提升推理技能。
- Hindsight链(CoH;Liu等人,2023)通过明确地向模型展示一系列带有反馈的过去输出,鼓励模型改进自己的输出。
步骤2:记忆

我们可以将大脑中的不同记忆类型映射到LLM智能体架构中的组件
- 感觉记忆:这部分记忆捕捉即时感官输入,如我们看到、听到或感受到的。在提示工程和AI模型的上下文中,提示词充当瞬时输入,类似于瞬间触摸或感觉。它是触发模型处理的初始刺激。
- 短期记忆:短期记忆暂时保存与当前任务或对话相关的信息。在提示工程中,这相当于保留最近的聊天历史。这种记忆使智能体在整个交互过程中保持上下文和连贯性,确保响应与当前对话对齐。在代码中,你通常将其添加为对话历史。
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.agents import AgentExecutor
from langchain.agents import create_openai_functions_agent
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = [retriever_tool]
agent = create_openai_functions_agent(
llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
- 长期记忆:长期记忆存储事实知识和程序指令。在AI模型中,这其实就是用于训练和微调的数据。此外,长期记忆支持RAG框架的操作,使智能体能够访问并整合学习到的信息到其响应中。它就像是一个全面的知识库,agent基于它来生成有意义且相关的输出。在代码中,通常来说就是向量化数据库:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader("https://neurons-lab.com/")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
步骤3:工具
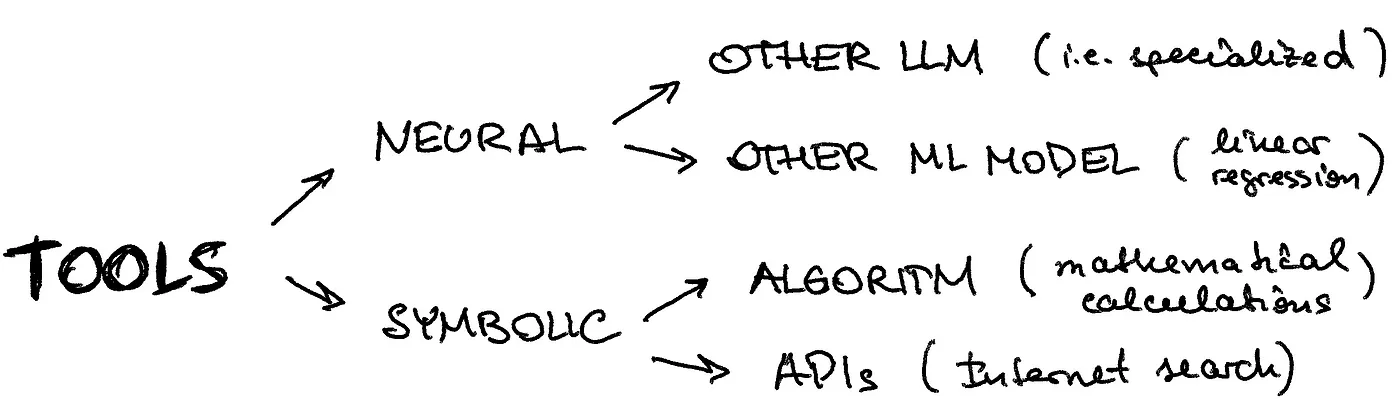
实践中,智能体的增强可以通过添加独立的推理线(可以是另一个领域特定的LLM或其他机器学习模型,用于图像分类)或者基于规则、API来进行。
ChatGPT插件和OpenAI API函数调用是LLMs实际使用工具的典型例子。
- 内置的Langchain工具:Langchain有多种内置工具,从互联网搜索、Arxiv工具包到Zapier和Yahoo Finance。我们将尝试使用Tavily提供的互联网搜索进行一个简单的实验:
from langchain.utilities.tavily_search import TavilySearchAPIWrapper
from langchain.tools.tavily_search import TavilySearchResults
search = TavilySearchAPIWrapper()
tavily_tool = TavilySearchResults(api_wrapper=search)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.0)
agent_chain = initialize_agent(
[retriever_tool, tavily_tool],
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
- 自定义工具:定义自己的工具也非常简单。用一个计算字符串长度的工具来举个例。需要使用@tool装饰器来让Langchain知道它,然后,还需要提供输入和输出的类型,最重要的是三个引号之间的函数注释——这将告诉智能体这个工具能做什么,并将其与其他工具的描述进行比较:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
@tool
def calculate_length_tool(a: str) -> int:
"""The function calculates the length of the input string."""
return len(a)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.0)
agent_chain = initialize_agent(
[retriever_tool, tavily_tool, calculate_length_tool],
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
你可以在这个脚本中看到它是怎么工作的,但也会看到一个错误——它没有拉取到Neurons Lab公司的正确描述,尽管调用的长度计算函数是对的,但最终结果还是错误的。
步骤4:整合到一起
我在这个脚本中提供了一个组合在一起的干净版本。注意,我们要能轻松地识别及定义出:
- 所有类型的工具(搜索、自定义工具等)
- 所有类型的记忆(对应感观的是提示词、短期记忆的是消息历史以及提示词内的sketchpad,长期记忆则对应向量数据库的检索)
- 任意类型的规划策略(作为从LLMOps系统中提取的提示词的一部分)
最终的智能体定义看起来会是这样的:
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
如脚本的输出所示(你也可以自己运行它),它解决了上一部分与工具相关的问题。这和直接调用大模型有什么区别呢,我们定义了一个完整的架构,在这里短期记忆起着关键作用,我们的智能体获得了消息历史和推理结构中的sketchpad,这使得它能够获取正确的网站描述并计算其长度。
最后
希望这次对LLM智能体架构核心元素的介绍能够设计出用于认知任务的实用机器人。最后,我想再次强调拥有智能体的所有元素的重要性。正如我们所看到的,缺少短期记忆或工具的不完整描述可能会干扰智能体的推理,甚至对于像摘要生成和长度计算这样非常简单的任务也会提供错误答案。
