什么是1-bit LLM
生成式AI领域正在飞速发展,最新加入这个快速演进领域的是一1比特LLMs。你可能不相信,但它可以改变很多事情,并有助于消除与LLMs相关的一些最大挑战,尤其是它们庞大尺寸问题。
通常情况下(不总是这样),无论是LLMs还是逻辑回归等机器学习模型,其权重都以32位浮点数或16位浮点数的形式存储。
这就是为什么我们无法在本地系统和生产环境中使用GPT等大型模型的原因。因为这些模型具有大量权重,由于权重的高精度值导致模型体积庞大。
假设我们有一个名为“MehulGPT”的LLM,它有70亿个参数(类似于Mistral或Llama-7B),使用32位精度(4字节)。该模型将占用的总内存为:
- 总内存 = 单个权重的大小 * 权重数量
总内存 = 4字节 * 7,000,000,000
总内存 = 28,000,000,000字节
将其转换为GB,我们得到:
- 总内存 = 28,000,000,000字节 / 1024³ 字节每GB
总内存 ≈ 26.09 GB
这是一个巨大的体积,因此许多设备都无法使用它,包括手机,因为它们没有这么大的存储空间或硬件能力来运行这些模型。
那么,如何使LLMs适用于小型设备和手机呢?
1比特LLMs
在1比特LLMs中,仅使用1比特(即0或1)来存储权重参数,而传统LLMs使用32/16比特。这大大减少了总体积,从而使小型设备也能使用LLMs。假设是“MehulGPT”的1比特版本。这次占用的内存为:
- 总内存 = 单个权重的大小 * 权重数量
总内存 = 0.125字节 * 7,000,000,000
总内存 = 875,000,000字节
将其转换为千兆字节(GB),我们得到:
- 总内存 = 875,000,000字节 / 1024³ 字节每GB
总内存 ≈ 0.815 GB
1比特 = 0.125字节
因此,节省了大量的计算和存储资源。
这是不是和量化类似?
有的读者可能不了解量化,它是一种通过降低权重的精度来减小模型大小的方法,例如从32位减少到8位,从而减小4倍的大小。使用的位数越低,模型的大小就越小,但性能也会受到影响。
1比特LLMs类似于量化思想,但有所不同。在量化中,我们降低了精度(所以如果一个权重值是2.34567890656373…,它可能会被减少到2.3456)。
在1比特LLM中,每个权重将仅由二进制运算符(0,1)表示,因此模型更为精简。进行了一些主要的架构更改,以确保与传统LLMs相比,性能不受影响。
BitNet b1.58
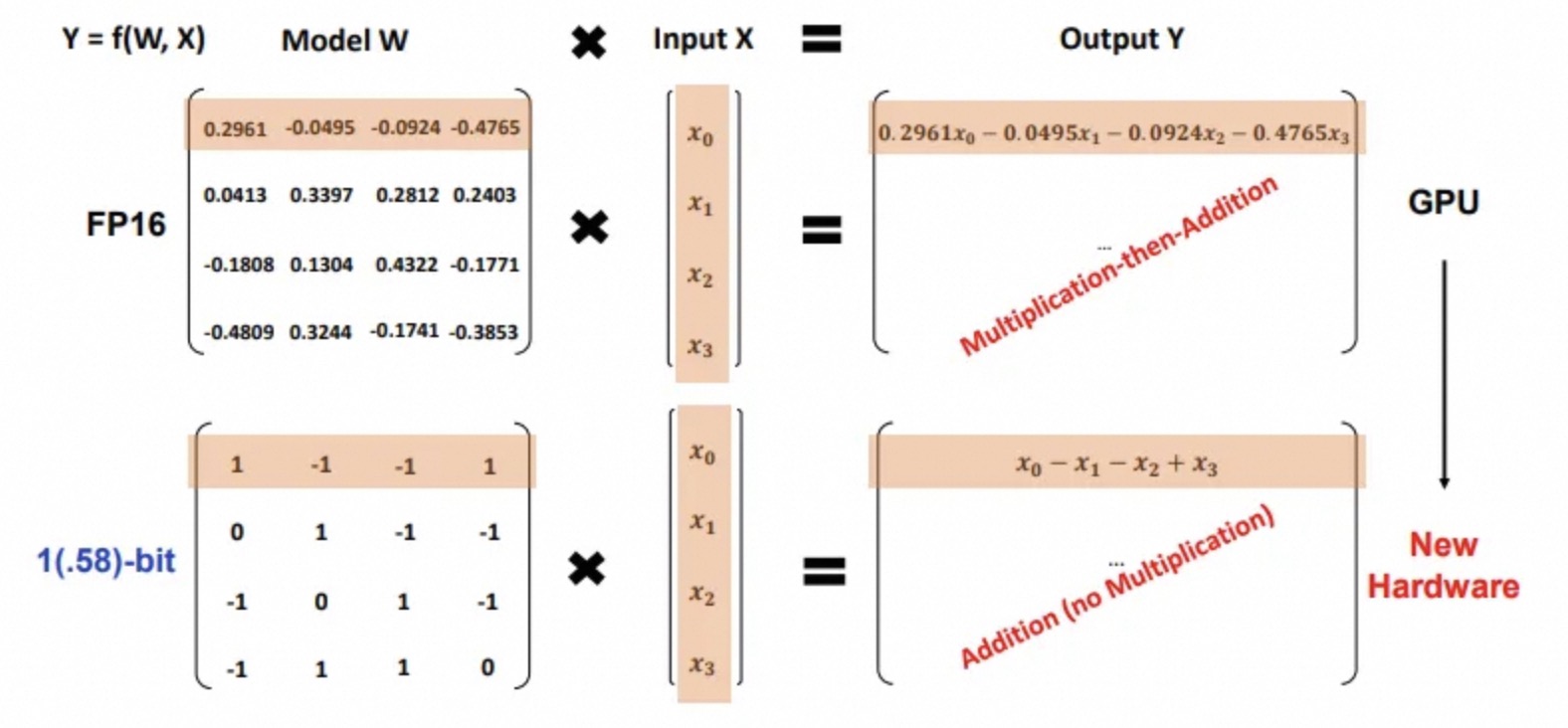
BitNet b1.58是首款1比特LLM,目前使用1.58比特/权重(因此并非严格的1比特LLM),其中权重可以有3个可能的值(-1,0,1)。
对于1.58比特: 1)权重只有-1,0,1的值。 2)由于值仅为-1,0,1,因此不需要乘法操作。
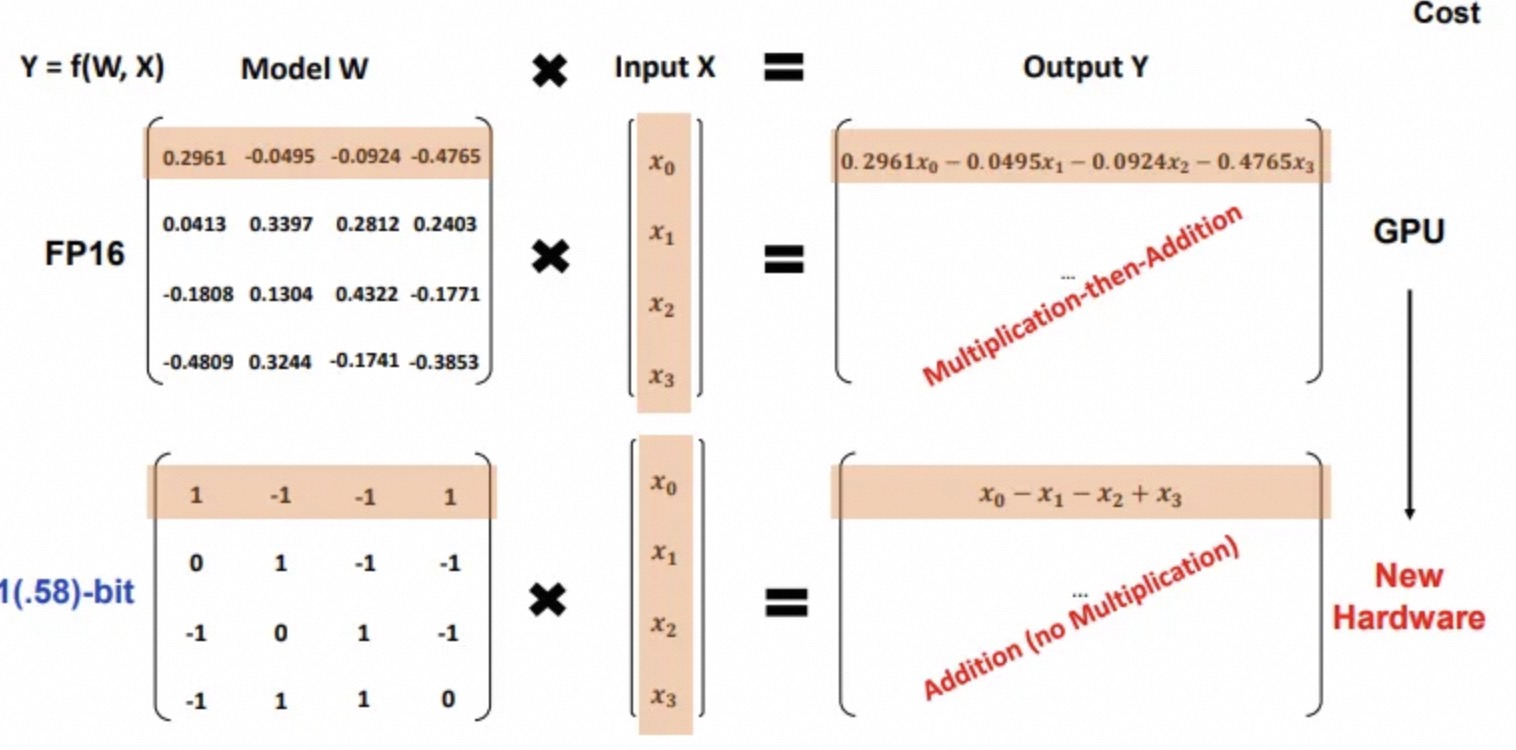
根据论文中所说:
BitNet b1.58在困惑度和终端任务性能方面与16位浮点数LLM基线相当。
它提供了更快的处理速度,并且比传统模型使用更少的GPU内存。
模型最小化矩阵乘法中的乘法操作,提高了优化和效率。
包括用于系统级优化的量化函数,并集成了类似于LLaMA的组件,如RMSNorm和SwiGLU。
注意:我暂时避开了上面提到的术语,因为解释它们需要另写一篇文章。
该模型目前尚未公开,因此还没有被公开测试。但是,这看起来非常有前景,如果它声称的优点属实,我们将迎来一场盛宴!
