Java字节码浅析(二)
条件语句
像if-else, switch这样的流程控制的条件语句,是通过用一个指令进行两个值的比较,然后根据结果跳转到另一条字节码来实现的。
循环语句包括for循环,while循环,它们的实现方式也很类似,但除了一点,它们通常都会包含一条goto指令,以便字节码实现循环执行。do-while循环不需要goto指令,因为它的条件分支是在字节码的末尾。更多细节请参考循环语句一节。
有一些指令可以用来比较两个整型或者两个引用,然后执行某个分支,这些操作都能在单条指令里面完成。而像double,float,long这些值需要两条指令。首先得去比较两个值,然后根据结果,会把1,0或者-1压到栈里。最后根据栈顶的值是大于,等于或者小于0来判断应该跳转到哪个分支。
我们先来介绍下if-else语句,然后再详细介绍下分支跳转用到的几种不同的指令。
if-else
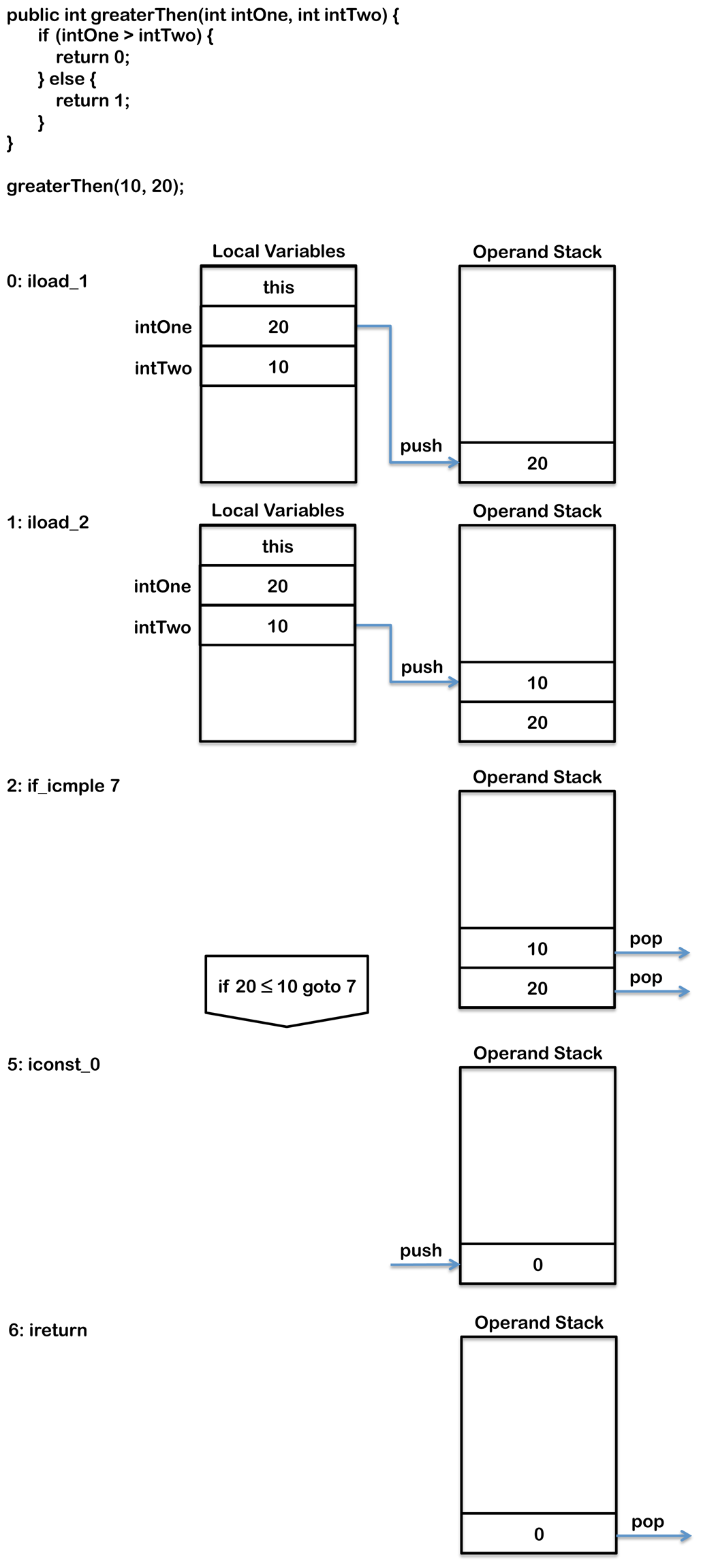
下面的这个简单的例子是用来比较两个整数的:
public int greaterThen(int intOne, int intTwo) {
if (intOne > intTwo) {
return 0;
} else {
return 1;
}
}方法最后会编译成如下的字节码:
0: iload_1
1: iload_2
2: if_icmple 7
5: iconst_0
6: ireturn
7: iconst_1
8: ireturn首先,通过iload1, iload2两个指令将两个入参压入操作数栈中。if_icmple会比较栈顶的两个值的大小。如果intOne小于或者等于intTwo的话,会跳转到第7条字节码处执行。可以看到这里和Java代码里的if语句的条件判断正好相反,这是因为在字节码里面,判断条件为真的话会跑到else分支里面去执行,而在 Java代码里,判断为真会进入if块里面执行。换言之,if_icmple判断的是如果if条件不为真,然后跳过if块。if代码块里对应的代码是第5,6条字节码,而else块对应的是第7,8条。
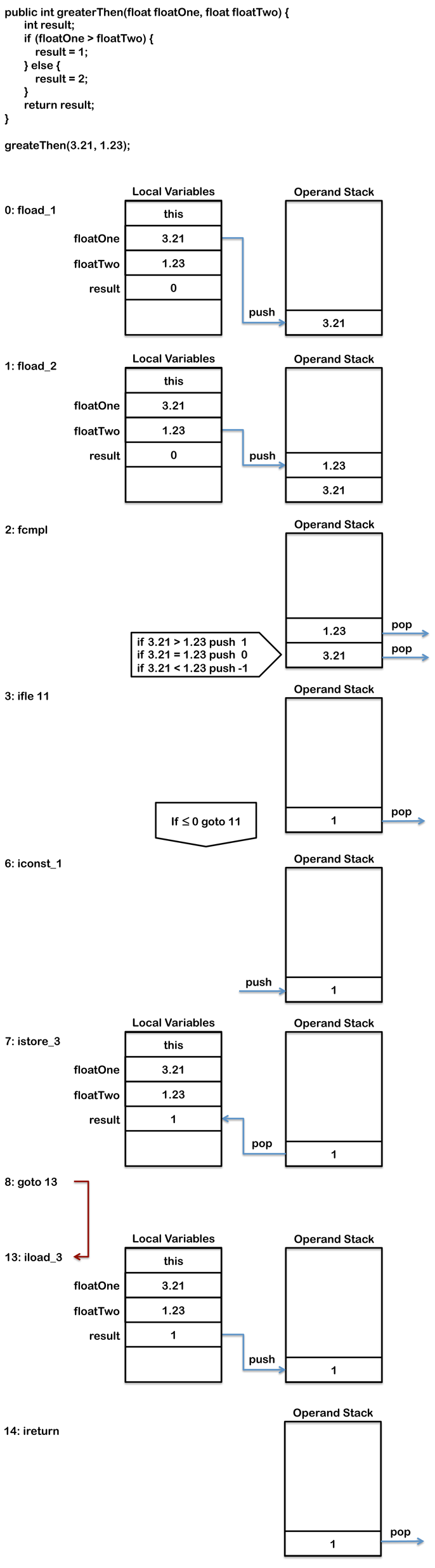
下面的代码则稍微复杂了一点,它需要进行两次比较。
public int greaterThen(float floatOne, float floatTwo) {
int result;
if (floatOne > floatTwo) {
result = 1;
} else {
result = 2;
}
return result;
}编译后会是这样:
0: fload_1
1: fload_2
2: fcmpl
3: ifle 11
6: iconst_1
7: istore_3
8: goto 13
11: iconst_2
12: istore_3
13: iload_3
14: ireturn在这个例子中,首先两个参数会被fload1和fload2指令压入栈中。和上面那个例子不同的是,这里需要比较两回。fcmple先用来比较栈顶的floatOne和floatTwo,然后把比较的结果压入操作数栈中。
* floatOne > floatTwo –> 1
* floatOne = floatTwo –> 0
* floatOne < floatTwo –> -1
* floatOne or floatTwo = NaN –> 1然后通过ifle进行判断,如果前面fcmpl的结果是<=0的话,则跳转到11行处的字节码去继续执行。
这个例子还有一个地方和前面不同的是,它只在方法末有一个return语句,因此在if代码块的最后,会有一个goto语句来跳过else块。goto语句会跳转到第13条字节码处,然后通过iload_3将存储在局部变量区第三个位置的结果压入栈中,然后就可以通过return指令将结果返回了。
除了比较数值的指令外,还有比较引用是否相等的(==),以及引用是否等于null的(== null或者!=null),以及比较对象的类型的(instanceof)。
| if_icmp<cond> | 这组指令用来比较操作数栈顶的两个整数,然后跳转到新的位置去执行。<cond>可以是:eq-等于,ne-不等于,lt-小于,le-小于等于,gt-大于, ge-大于等于。 |
| if_acmp<cond> | 这两个指令用来比较对象是否相等,然后根据操作数指定的位置进行跳转。 |
| ifnonnull ifnull | 这两个指令用来判断对象是否为null,然后根据操作数指定的位置进行跳转。 |
| lcmp | 这个指令用来比较栈顶的两个长整型,然后将结果值压入栈中: 如果value1>value2,压入1,如果value1==value2,压入0,如果value1<value2压入-1. |
| fcmp<cond> l g dcomp<cond> | 这组指令用来比较两个float或者double类型的值,然后然后将结果值压入栈中:如果value1>value2,压入1,如果value1==value2,压入0,如果value1<value2压入-1. 指令可以以l或者g结尾,不同之处在于它们是如何处理NaN的。fcmpg和dcmpg指令把整数1压入操作数栈,而fcmpl和dcmpl把-1压入操作数栈。这确保了比较两个值的时候,如果其中一个不是数字(Not A Number, NaN),比较的结果不会相等。比如判断if x > y(x和y都是浮点数),就会用的fcmpl,如果其中一个值是NaN的话,-1会被压入栈顶,下一条指令则是ifle,如果分支小于0则跳转。因此如果有一个是NaN的话,ifle会跳过if块,不让它执行。 |
| instanceof | 如果栈顶对象的类型是指定的类的话,则将1压入栈中。这个指令的操作数指定的是某个类型在常量池的序号。如果对象为空或者不是对应的类型,则将0压入操作数栈中。 |
| if<cond> | 将栈顶值和0进行比较,如果条件为真,则跳转到指定的分支继续执行。这些指令通常用于较复杂的条件判断中,在一些单条指令无法完成的情况。比如验证方法调用的返回值。 |
switch语句
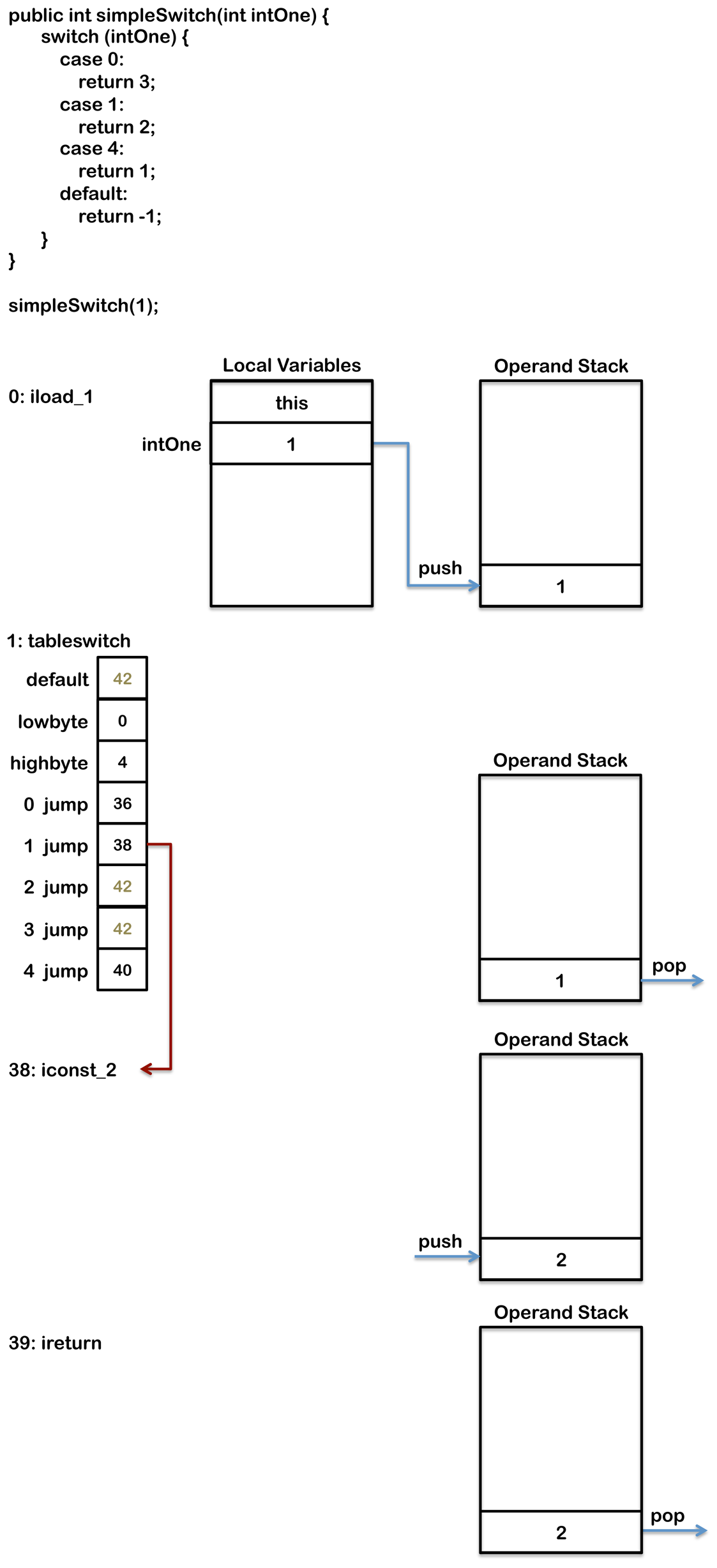
Java switch表达式的类型只能是char,byte,short,int,Character, Byte, Short,Integer,String或者enum。JVM为了支持switch语句,用了两个特殊的指令,叫做tableSwitch和lookupswitch,它们都只能操作整型数值。只能使用整型并不影响,因为char,byte,short和enum都可以提升成int类型。Java7开始支持String类型,下面我们会介绍到。tableswitch操作会比较快一些,不过它消耗的内存会更多。tableswitch会列出case分支里面最大值和最小值之间的所有值,如果判断的值不在这个范围内则直接跳转到default块执行,case中没有的值也会被列出,不过它们同样指向的是default块。拿下面的这个switch语句作为例子:
public int simpleSwitch(int intOne) {
switch (intOne) {
case 0:
return 3;
case 1:
return 2;
case 4:
return 1;
default:
return -1;
}
}编译后会生成如下的字节码
0: iload_1
1: tableswitch {
default: 42
min: 0
max: 4
0: 36
1: 38
2: 42
3: 42
4: 40
}
36: iconst_3
37: ireturn
38: iconst_2
39: ireturn
40: iconst_1
41: ireturn
42: iconst_m1
43: ireturntableswitch指令的0,1,4的值都对应case语句里面的值,它们指向的是对应的代码码的字节码。tableswitch指令同样有2,3的值,它们并不在case语句中,它们指向的是default代码块。当这条指令执行的时候,会判断操作数栈顶的值是否在最大值和最小值之间。如果不在的话,直接跳去default分支,也就是上面的第42行的字节码处。为了确保能找到default分支,它都是出现在tableswitch指令的第一个字节(如果需要内存对齐的话,则在补齐了之后的第一个字节)。如果栈顶的值在最大最小值的范围内,则用它作为tableswtich内部的索引,定位到应该跳转的分支。比如1的话,就会跳转至38行处继续执行。下图会演示这条指令是如何执行的:
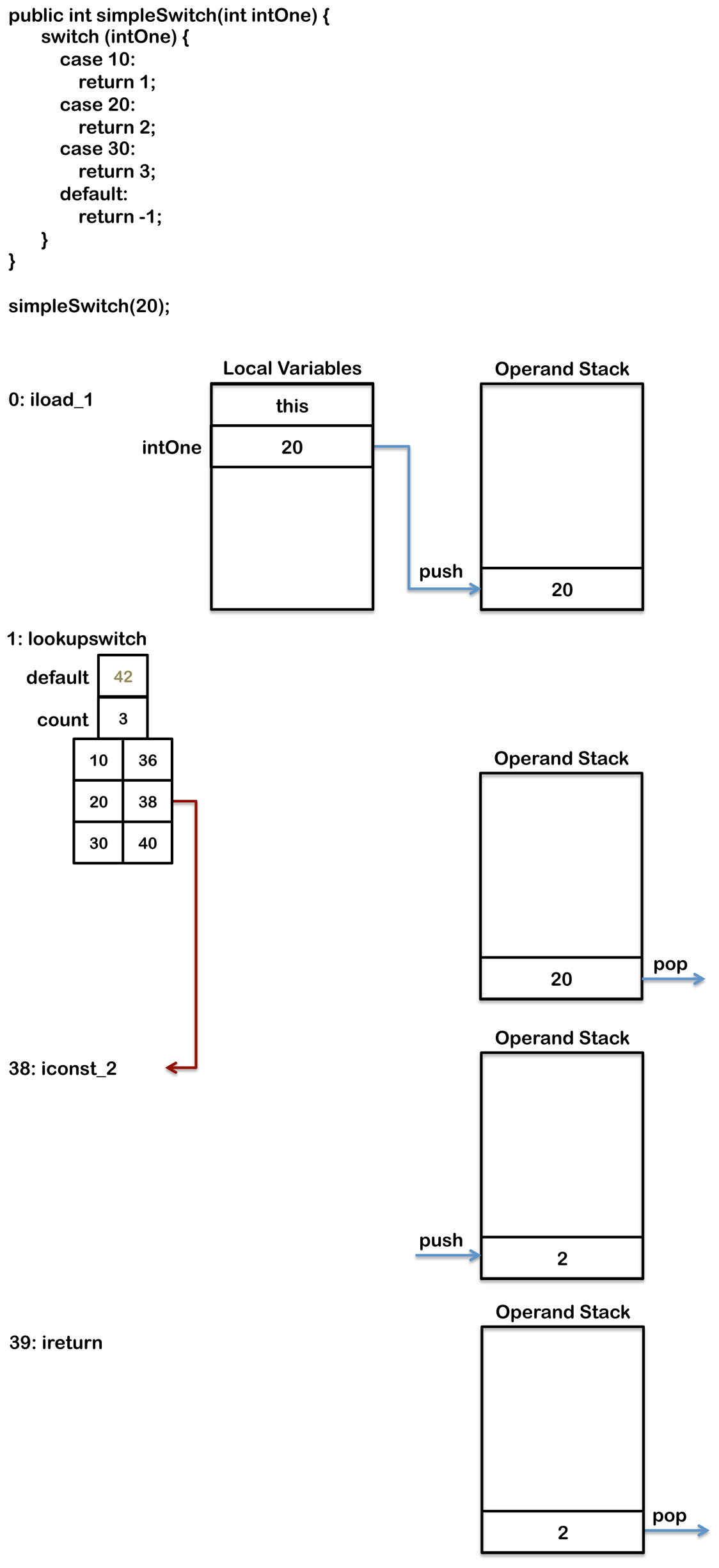
如果case语句里面的值范围太广了(也就是太分散了)这个方法就不太好了,因为它使用的内存太多了。因此当switch的case条件里面的值比较分散的时候,就会使用lookupswitch指令。这个指令会列出case语句里的所有跳转的分支,但它没有列出所有可能的值。当执行这条指令的时候,栈顶的值会和lookupswitch里的每个值进行比较,来确定要跳转的分支。执行lookupswitch指令的时候,JVM会在列表中查找匹配的元素,这和tableswitch比起来要慢一些,因为tableswitch直接用索引就定位到正确的位置了。当switch语句编译的时候,编译器必须去权衡内存的使用和性能的影响,来决定到底该使用哪条指令。下面的代码,编译器会生成lookupswitch语句:
public int simpleSwitch(int intOne) {
switch (intOne) {
case 10:
return 1;
case 20:
return 2;
case 30:
return 3;
default:
return -1;
}
}生成后的字节码如下:
0: iload_1
1: lookupswitch {
default: 42
count: 3
10: 36
20: 38
30: 40
}
36: iconst_1
37: ireturn
38: iconst_2
39: ireturn
40: iconst_3
41: ireturn
42: iconst_m1
43: ireturn为了确保搜索算法的高效(得比线性查找要快),这里会提供列表的长度,同时匹配的元素也是排好序的。下图演示了lookupswitch指令是如何执行的。
未完待续。
原创文章转载请注明出处:Java字节码浅析(二)
