AtomicLong还能更快一点吗
AtomicLong还能更快一点吗?让子弹再飞一会儿
我经常听别人说Java的原子类型(java.util.concurrent.atomic)非常快,在高并发的环境下表现很优秀。很多时候,原子类型确实能很高效的完成它们的任务。然而在有些场景下面,原子类型的竞争冲突带来的隐形开销会带来严重的性能问题。我们来看下原子类型是什么实现的,这样设计意味着什么。
所有的原子类型,比如AtomicLong, AtomicBoolean, AtomicReference等等,都是volatile值的一个包装。sun.misc.Unsafe的引入给它们带来了附加功能,它使得这些类型具备了CAS的能力。
CAS(compare-and-swap)本质上是现代CPU提供的一个原子指令,它旨在提供一个安全高效的非阻塞,多线程的数据操作能力。CAS和锁相比的最大优势在于,由于CAS没有仲裁,不会带来内核级别的负载。相反的,编译器发出了lock cmpxchg, lock xadd, lock addq等CPU指令,这是你从JVM层面调用指令的最快方式了。
在大多数情况下,低开销的CAS是锁原语的一个高效的替代品。然而,在竞争的场景下,CAS的开销也会呈指数级增长。
Dave Dice, Danny Hendler和Ilya Mirsky的一份很有意思的研究报告里证实了这个问题。我强烈推荐你读一下那篇论文,跟这篇文章相比,那篇论文包含的信息量要大得多。
我从这篇论文里整理出了一些概念,并进行了测试。很多Java程序员看了这个结果会觉得很惊讶,因为长久以来对CAS的性能都存在误区。
实现回避竞争控制的代码非常简单。CAS失败后不要直接循环,先等待一小段时间,让别的线程可以尝试更新。
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.LockSupport;
public class BackOffAtomicLong {
public static long bk;
private final AtomicLong value = new AtomicLong(0L);
public long get() {
return value.get();
}
public long incrementAndGet() {
for (;;) {
long current = get();
long next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public boolean compareAndSet(final long current, final long next) {
if (value.compareAndSet(current, next)) {
return true;
} else {
LockSupport.parkNanos(1L);
return false;
}
}
public void set(final long l) {
value.set(l);
}
}测试是在64位的Linux 3.5.0(x8664)上执行的,CPU是Intel(R) Core(TM) i7-3632QM 2.20GHz(8核),Java版本为64位1.7.025-b15。
和预料中一样,读竞争高的情况下,两个实现性能没有太大差别:
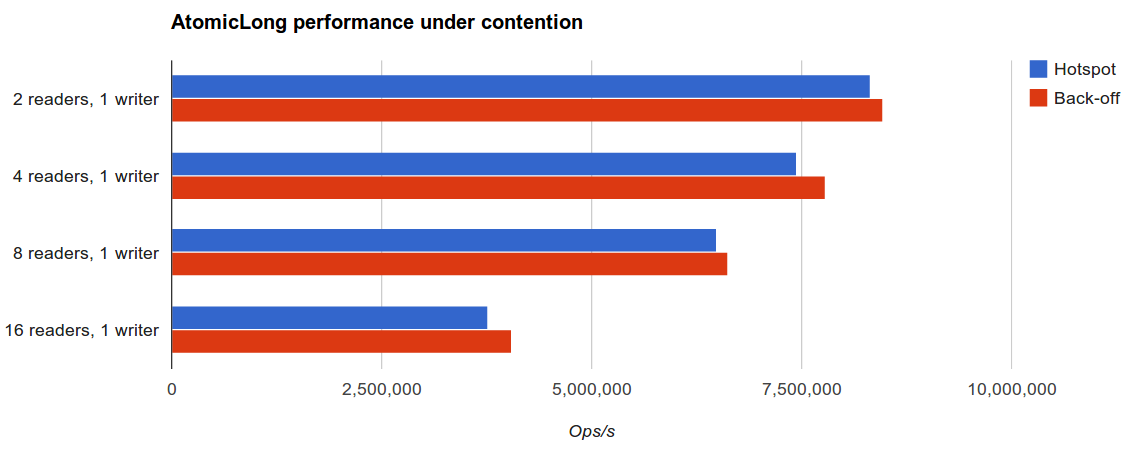
然而,写竞争激烈的话结果就很有意思了。这个场景暴露了Hotspot的AtomicLong的乐观重试机制的缺陷。
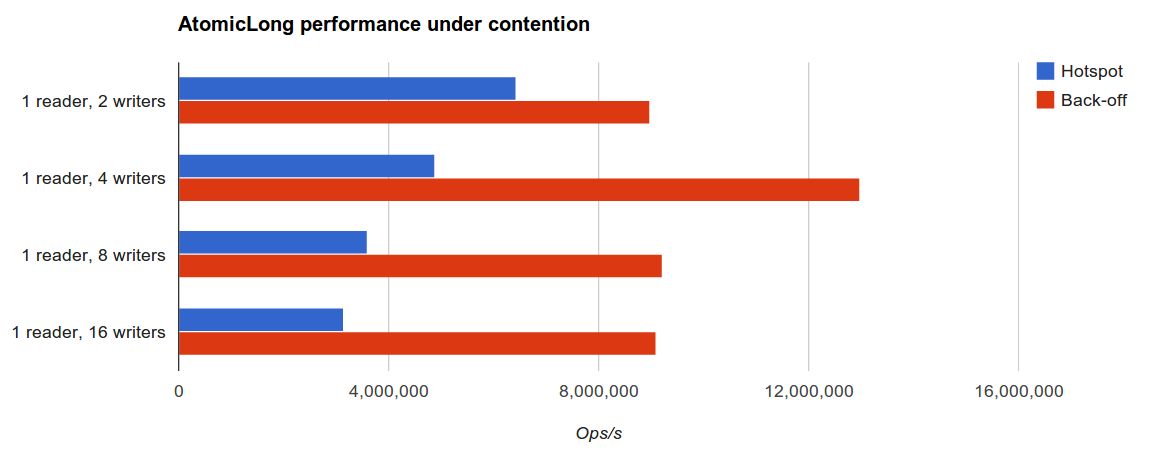
类似的,读写竞争都很高的时候,这个轻量级访问控制的好处也同样明显。

如果涉及到socket间通信的话,结果会大不相同。不过很不幸,这里丢了些英特尔Xeon平台的测试数据。如果你们有兴趣的话,可以把不同平台的结果发上来。
原创文章转载请注明出处:AtomicLong还能更快一点吗
